Știu că există persoane care consideră că era AI este în plină desfășurare, că tehnologia a ajuns la maturitate, dar eu sunt unul dintre cei care cred că Inteligența Artificială abia dacă ne poate arăta acum ce ne va aștepta în viitor. Sincer, de la alcătuire de text, la generare de imagini și video, până la sarcini mai complexe de gândire profundă, AI-ul este totuși ca un bebeluș care încearcă să înțeleagă ce se întâmplă de fapt în jurul lui. Am putea crede, așadar, că mai este mult până departe, dar dacă realizăm că dezvoltarea AI a fost exponențială, atunci asta ar însemna că în doar 2 – 3 ani capacitățile acestei tehnologii ne vor uimi cu adevărat.
Însă pentru a putea susține ritmul accelerat cu care Inteligența Artificială își antrenează propriile capacități, este nevoie și de hardware capabil. Iar de aici putem spune că intervine NVIDIA, care încearcă să demonstreze că are tot ce-i trebuie chiar de acum spre a-i putea pune la dispoziție AI-ului fix ceea ce are nevoie.

Prin noua serie de plăci video GeForce RTX 50, bazate pe arhitectura Blackwell, NVIDIA nu a ridicat la un alt nivel doar capacitățile grafice în jocuri și randarea 3D în general, ci a multiplicat capabilitățile AI către noi culmi.
Ce anume din noile plăci NVIDIA GeForce RTX 50 face ca tot ce înseamnă AI rulat local să meargă ca uns?
Vorbim în primul rând despre nucleele Tensor de generația a 5-a. Dacă nucleele CUDA sunt „muncitorii” buni la toate, nucleele Tensor sunt specialiștii în matematică complexă (multiplicări de matrici), esențiale pentru AI.

În seria GeForce RTX 50, acestea sunt mult mai eficiente și oferă o putere de calcul (măsurată în TOPS – Tera Operations Per Second) mult mai mare față de seria RTX 40 și celelalte anterioare (de exemplu, la GeForce RTX 5080 avem 336 Tensor Cores de generația a 5-a, în timp ce un GeForce RTX 3080 avea 272 Tensor Cores din a 3-a generație). Asta înseamnă că un model de limbaj (LLM) sau un generator de imagini va răspunde mult mai rapid. Și vom vedea că fix așa asta prin testele rulate de mine mai jos.
În al doilea rând, seria NVIDIA GeForce RTX 50 vine cu suport nativ pentru formatul FP4, care nu este disponibil pentru seriile anterioare, precum RTX 20 sau RTX 30. Suportul nativ pentru formatul FP4 este, probabil, „arma secretă” pentru rularea locală. AI-ul folosește diferite precizii matematice, iar până acum majoritatea modelelor rulau în format FP16 sau FP8.
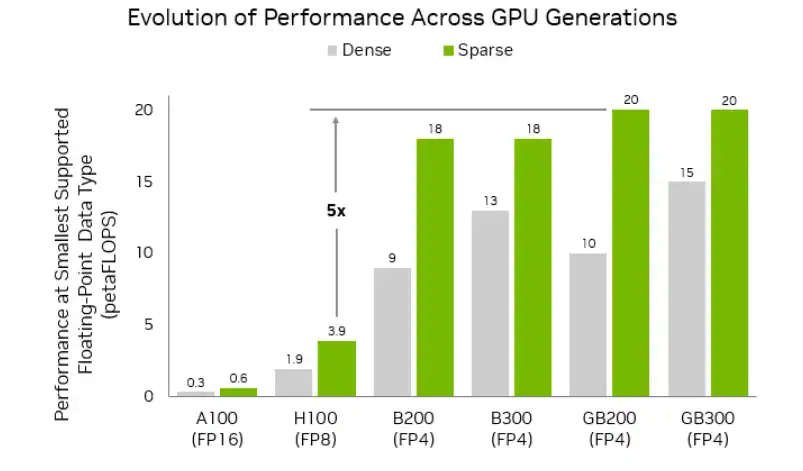
De ce contează FP4? Fiindcă permite comprimarea modelelor (cuantizare) mult mai agresiv, fără a pierde vizibil din calitate. Efectul practic este că modelele uriașe, care înainte aveau nevoie de 24 GB sau chiar 32 GB de memorie video (VRAM) pentru a rula, pot fi acum „înghesuite” în 12 GB sau 16 GB, rulând în același timp mult mai repede. Din nou, veți vedea că asta chiar contează.
Vorbim apoi și despre memoria video GDDR7. Modelele AI sunt „înfometate” după lățime de bandă. Nu contează doar câtă memorie ai, ci și cât de repede poți muta datele prin ea.
Trecerea la GDDR7 pe seria GeForce RTX 50 aduce o viteză de transfer mult mai mare, ceea ce elimină blocajele (bottlenecks) atunci când încarci parametri complecși ai unui model AI (cum ar fi în Stable Diffusion sau Llama 3, ca să dăm doar două exemple).
Nu în ultimul rând, motoarele Transformer de generația a 2-a fac diferența în favoarea GeForce RTX 50 față de generațiile anterioare ale plăcilor video de la NVIDIA.
Multe dintre AI-urile moderne (inclusiv ChatGPT) se bazează pe arhitectura „Transformer”. Arhitectura Blackwell include hardware dedicat care știe să gestioneze dinamic aceste modele, ajustând precizia calculelor în timp real pentru a maximiza performanța acolo unde este nevoie.
În esență, dacă vrei să rulezi un asistent AI local sau să generezi imagini și video instantaneu, seria NVIDIA GeForce RTX 50 face ca aceste sarcini să nu mai pară un „test de stres” pentru calculator, ci o rulare fluidă.
Cum am testat eu sarcinile AI rulate local pe un laptop cu placă video NVIDIA GeForce RTX 5080

Pentru a nu lăsa totul la nivel de explicații teoretice și a exemplifica capabilitățile NVIDIA GeForce RTX 50 în materie de rulare locală AI, am folosit un laptop Lenovo Legion Pro 7 (16IAX10H). Aparte de placa video dedicată NVIDIA GeForce RTX 5080 Laptop, acest PC se mai bazează pe un procesor Intel Core Ultra 9 275HX, pe 32 GB memorie RAM DDR5 și pe un SSD de 1TB, de tip M.2 PCIe Gen4 x4, printre altele.
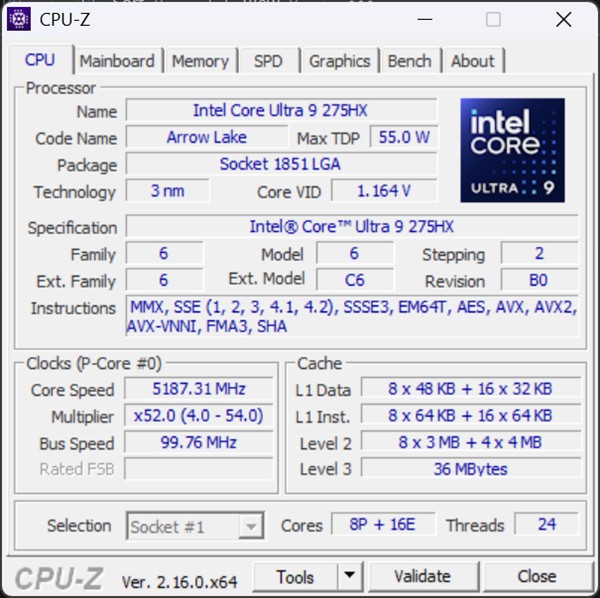
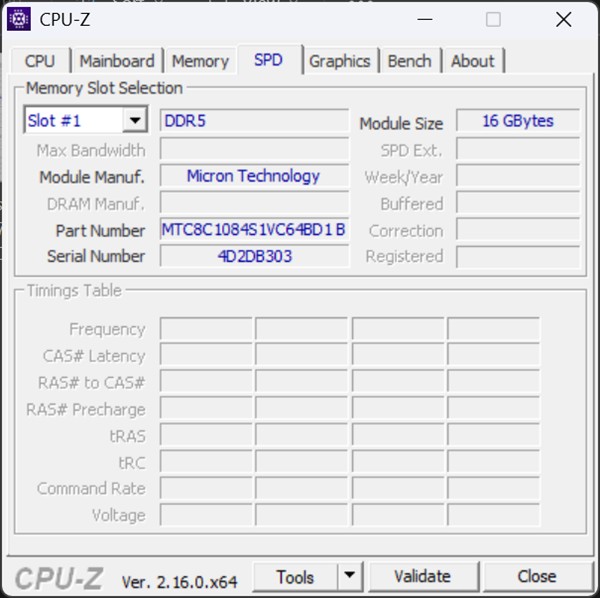
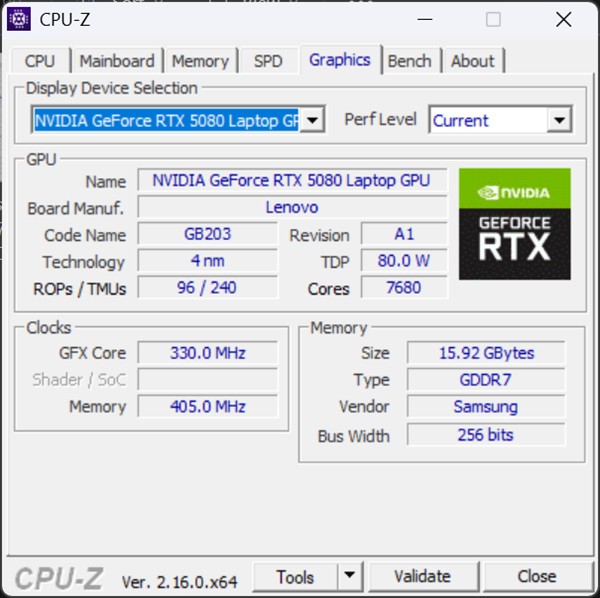
Pentru că am rulat teste de benchmark, dar și anumite sarcini bazate pe AI local, m-am gândit să vă arăt nu doar rezultatele pe care le obține laptopul când pune la lucru placa video dedicată NVIDIA GeForce RTX 5080, ci să avem și ceva comparație. Adică, cum nu am mai rulat astfel de teste și sarcini AI în trecut, ar cumva irelevante pentru voi cifrele seci, fără a le putea compara cu altceva.
Lenovo Legion Pro 7 (16IAX10H) îți dă posibilitatea de a folosi strict placa video dedicată (dGPU) în sarcinile care o solicită sau de a o dezactiva complet și a te baza doar pe CPU cu al său accelerator grafic integrat și cu ale sale nuclee NPU.
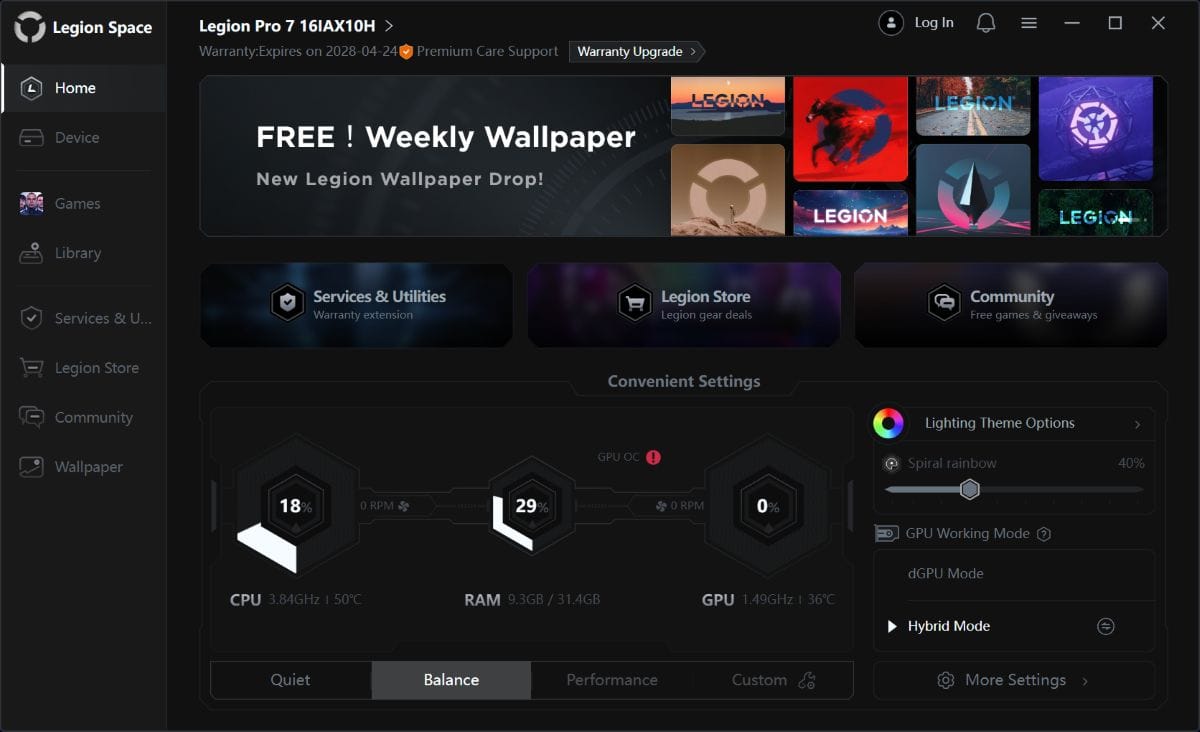
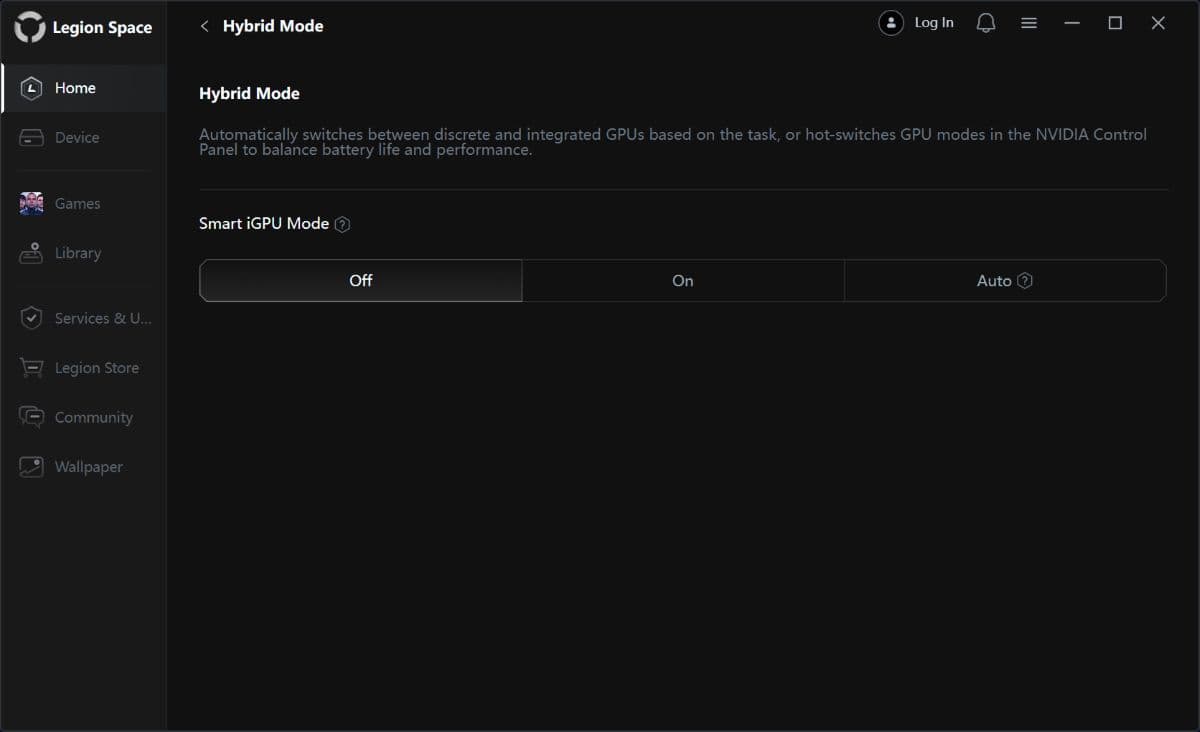
Prima dată am dezactivat placa video dedicată și am rulat testele și sarcinile AI, pentru ca doua oară să pun la treabă în fix aceleași scenarii NVIDIA GeForce RTX 5080 Laptop. Diferențele au fost uriașe, așa cum vedem prima dată din teste de benchmark sintetice, unele însă foarte evoluate și relevante. Mă refer la testele de la UL Solution prinse în suita Procyon. Dintre acestea l-am ales pe AI Image Generation Benchmark – Stable Diffusion 1.5 și pe AI Text Generation Benchmark, unde am rulat modelele PHI 3.5, MISTRAL 7B, LLAMA 3.1 și LLAMA 2.
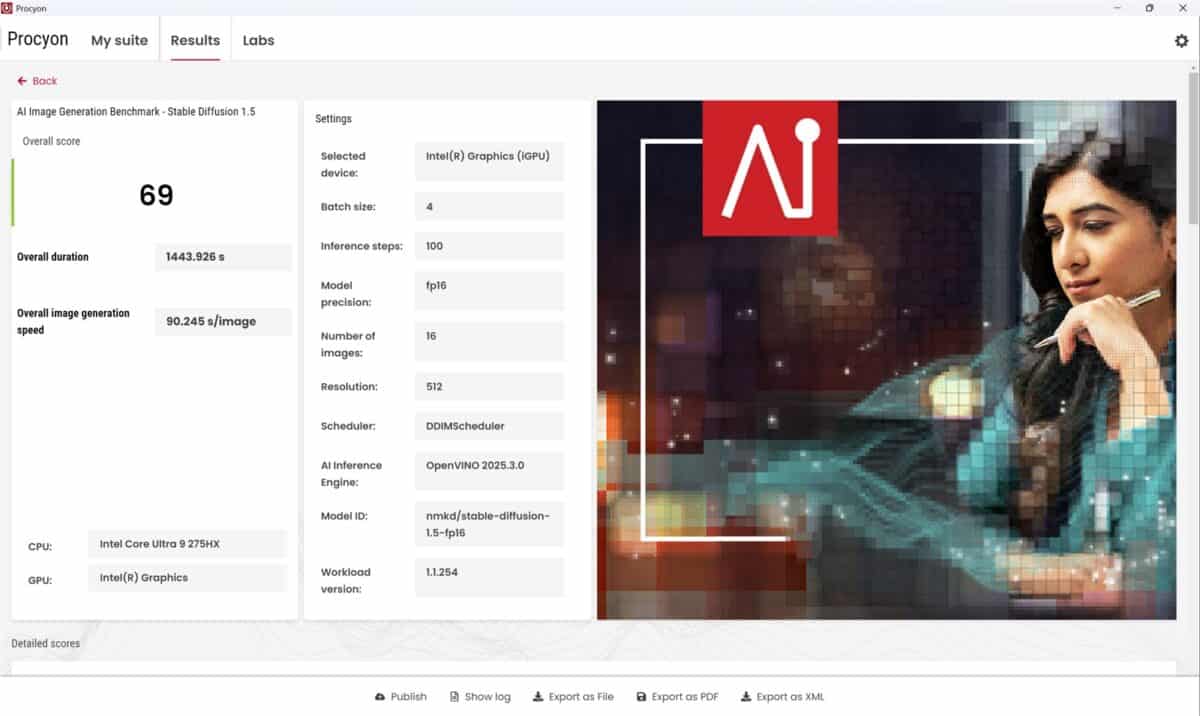
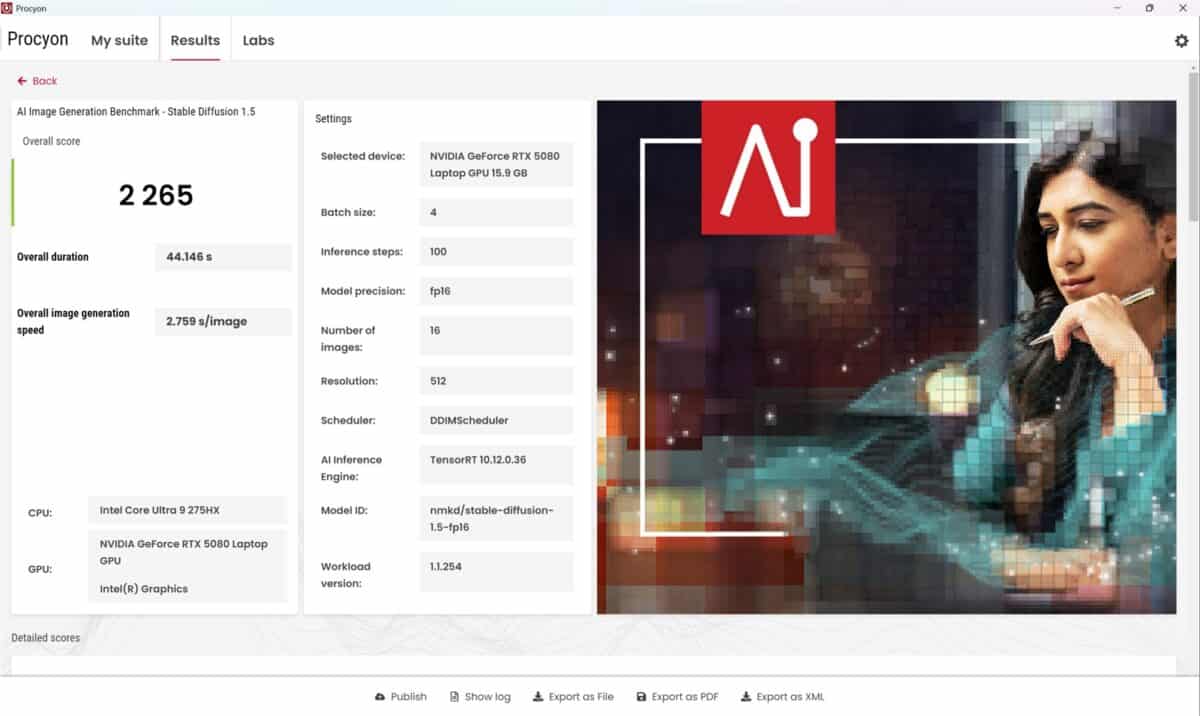
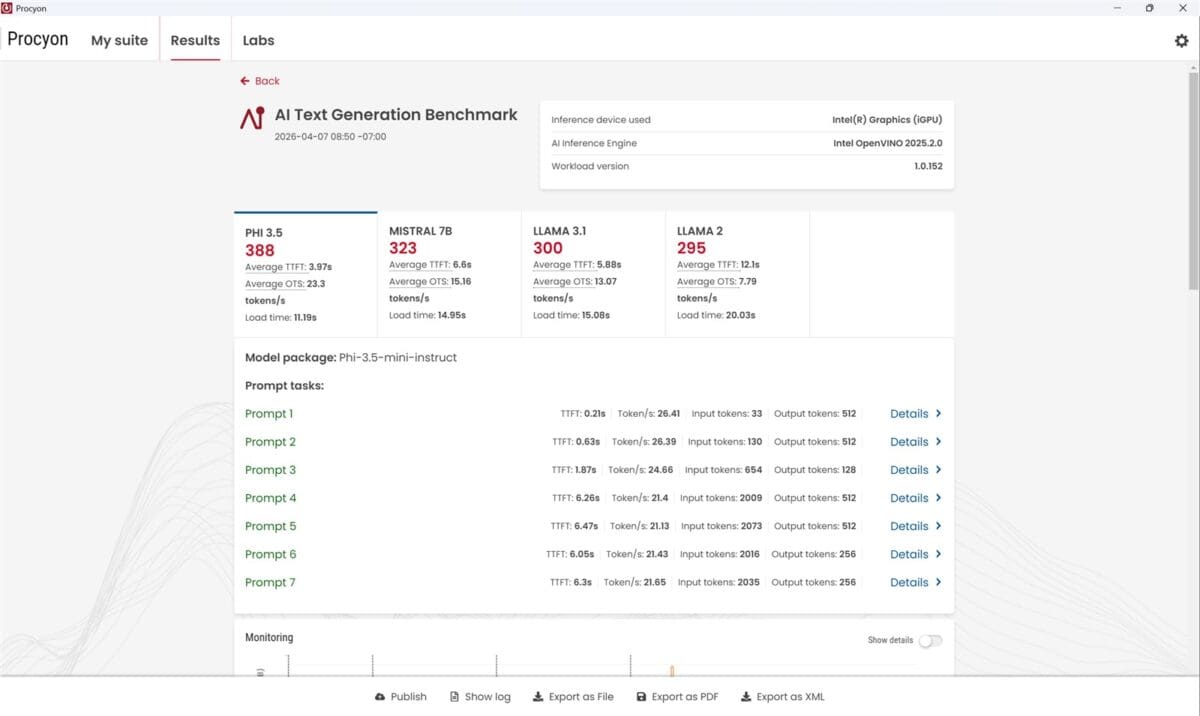
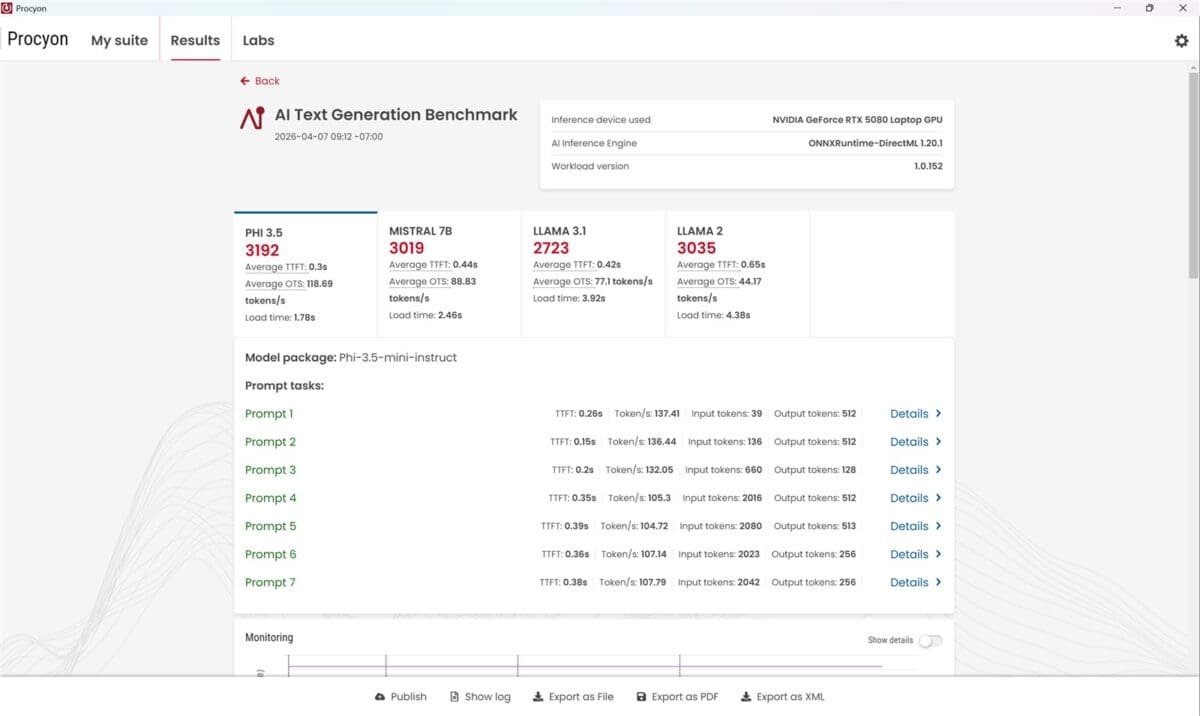
Vedem mai sus în primele capturi de ecran din fiecare set de teste că atunci când laptopul a rulat doar bazându-se pe CPU scorurile au fost de circa 32 de ori mai mici, respectiv de aproximativ 10 ori mai scăzute decât când AI-ul a fost rulat și prin placa NVIDIA GeForce RTX 5080.
Unii mai cârcotași ar putea spune că sunt doar niște teste de benchmark, nu sunt relevante pentru viața reală. Ei bine, pentru aceștia am mers mai departe cu alte trei încercări.
Prima dată am folosit programul LM Studio, în care am încărcat și pus la treabă modelul openai/gpt-oss-20b. Am pus aceeași întrebare, aceeași solicitare de două ori, prima dată cu placa video NVIDIA GeForce RTX 5080 Laptop dezactivată, a doua oară cu aceasta pusă la treabă de LM Studio.
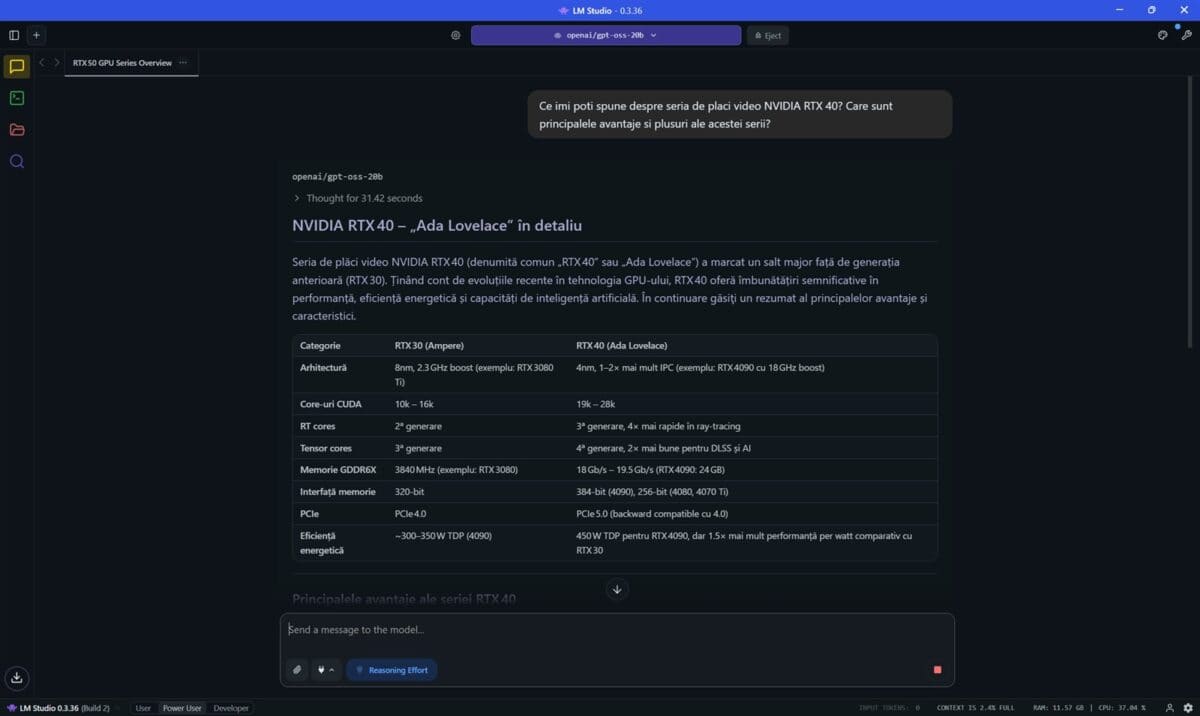
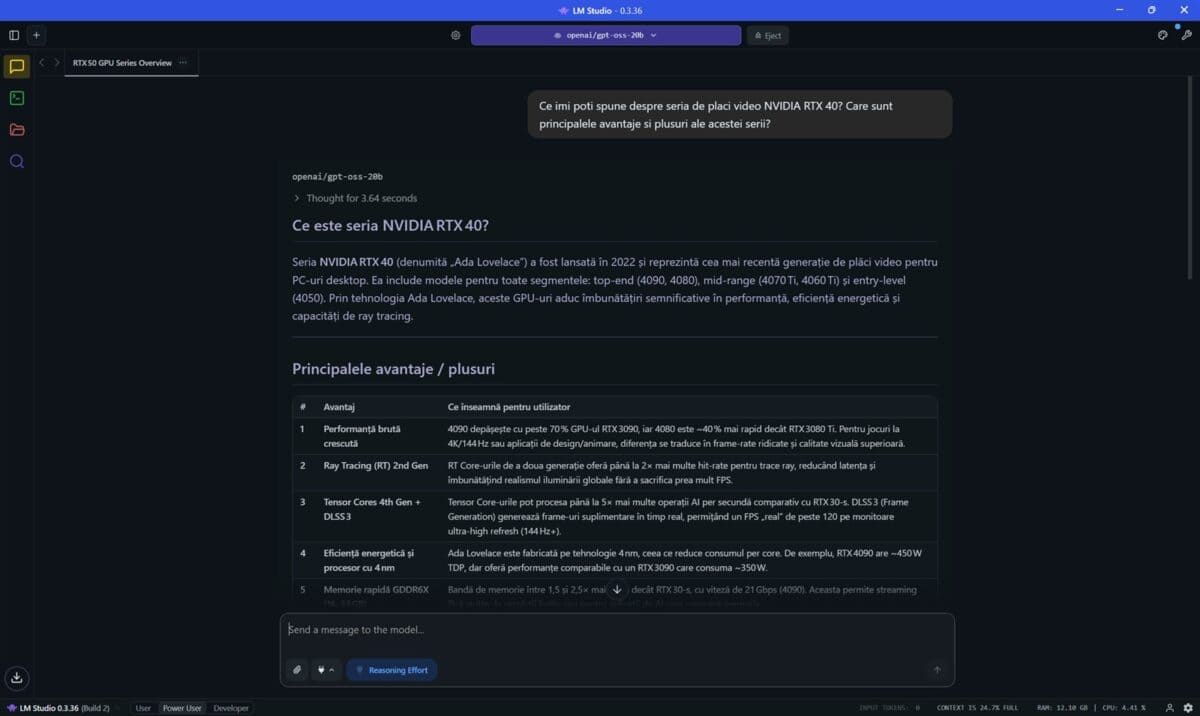
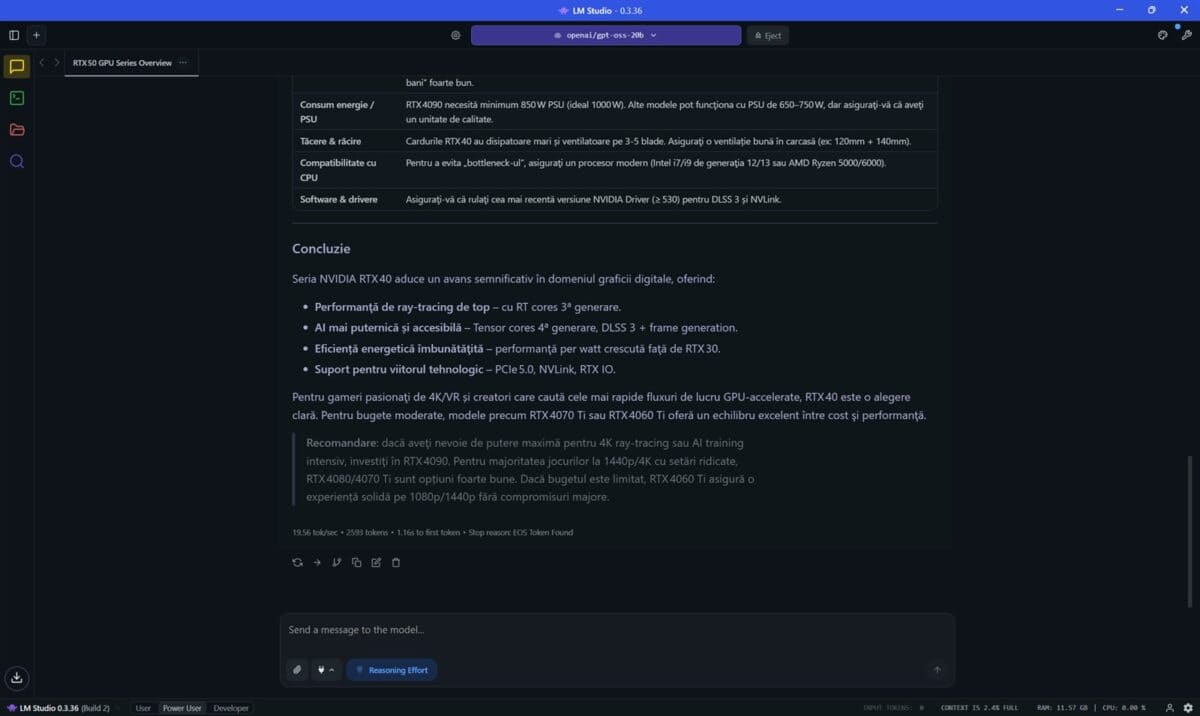
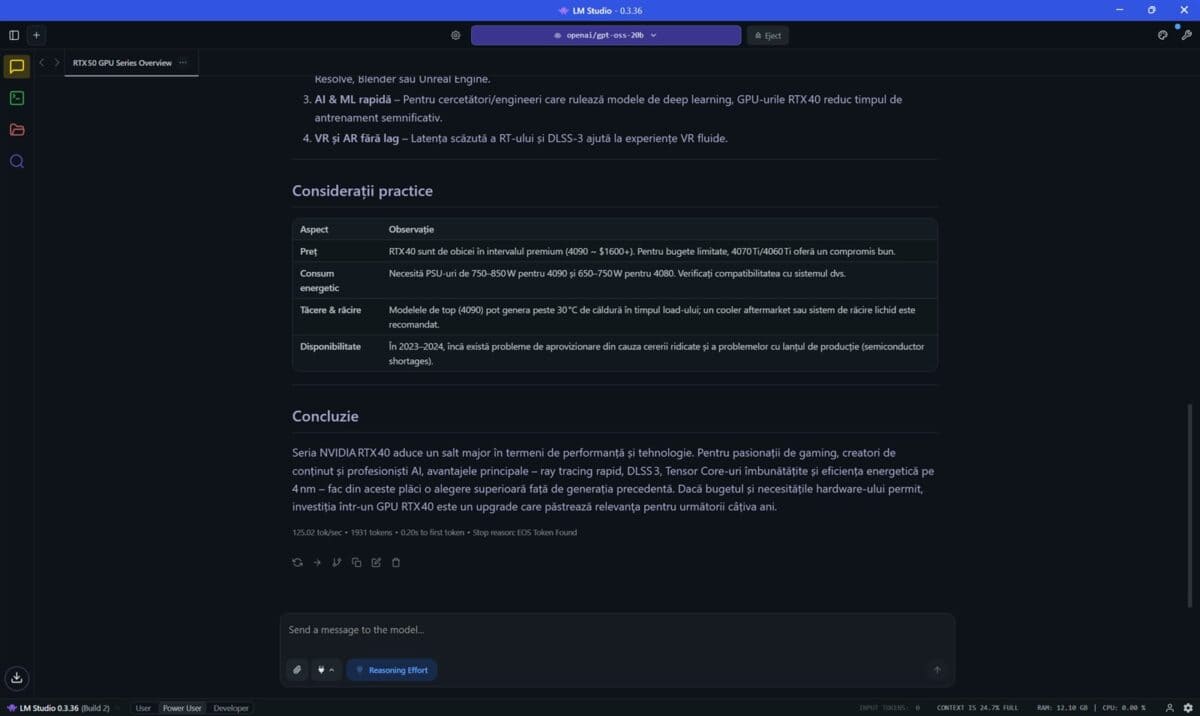
Din nou observăm că diferențele sunt uriașe, vorbim de fapt de un răspuns ce a început a fi generat după peste 31 de secunde de gândire în primul caz (doar cu CPU) față de numai 3.64 secunde când GeForce RTX 5080 Laptop și-a folosit capacitățile. Totodată, doar cu CPU vorbim despre o viteză de doar 19.56 tokeni / secundă, față de 125.02 tok/sec când placa video NVIDIA s-a ocupat de generarea răspunsului.
O a doua modalitate prin care am testat modelul openai/gpt-oss-20b a fost prin intermediul unui script Llama.cpp care rulează direct în Windows PowerShell. Am solicitat din noul LLM-ului aceeași cerință, iar răspunsul a fost generat conform capturilor de ecran de mai jos:
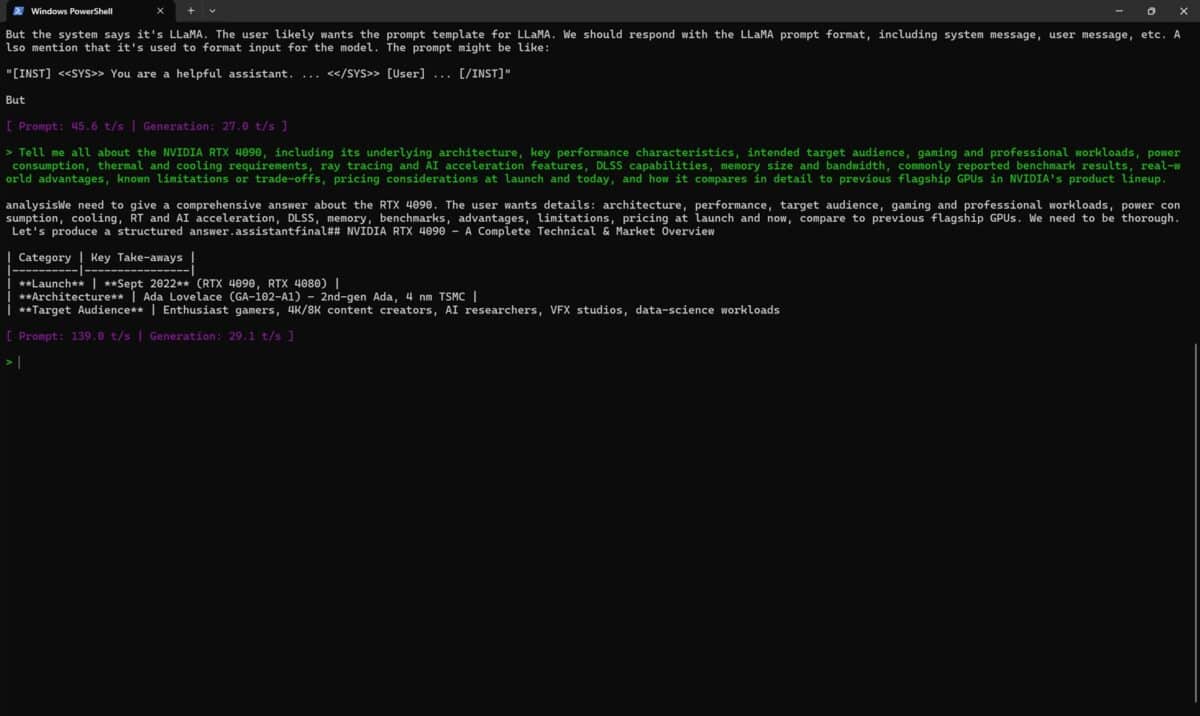
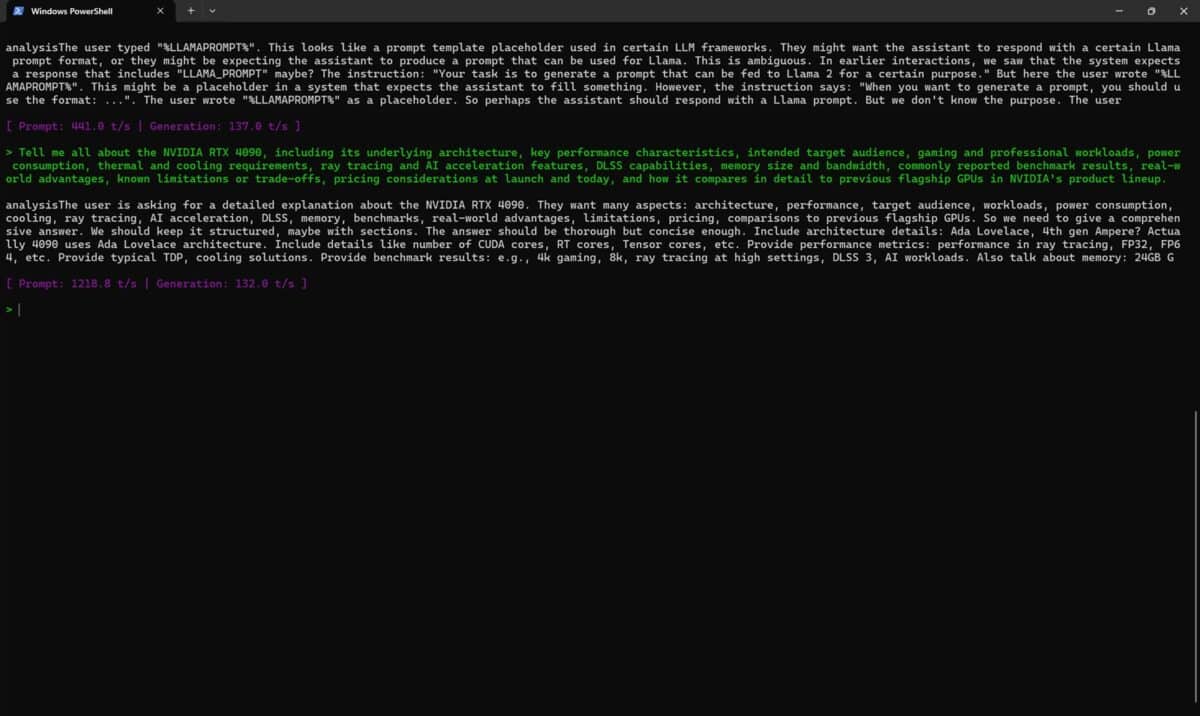
Vedem că atunci când de generarea răspunsului s-a ocupat doar CPU-ul a fost vorba despre o viteză de înțelegere a promptului de 139.0 t/s (tokeni / secundă), cu un răspuns dat cu 29.1 t/s. Când am solicitat ajutorul plăcii NVIDIA GeForce RTX 5080 Laptop, vitezele au fost cu totul altele, mai precis 1218.8 t/s cu 132.0 t/s. Cam mari diferențele, din nou cu mult în favoarea NVIDIA GeForce RTX 5080 Laptop !
O aplicație ce rulează AI local din ce în ce mai folosită este ComfyUI, iar pentru ultimele teste eu am bifat două versiuni: ComfyUI 0.3.5 și ComfyUI 0.8.25. Deosebirile dintre cele două țin mai mult de interfață, prima rulează într-o pagină de browser, după un script, a doua este o aplicație propriu-zisă, cu installer dedicat și interfață proprie.
Ca și mai sus, pentru test am rulat aceleași template-uri în primul caz doar cu CPU-ul laptopului, iar în al doilea cu NVIDIA GeForce RTX 5080 intrată în schemă.
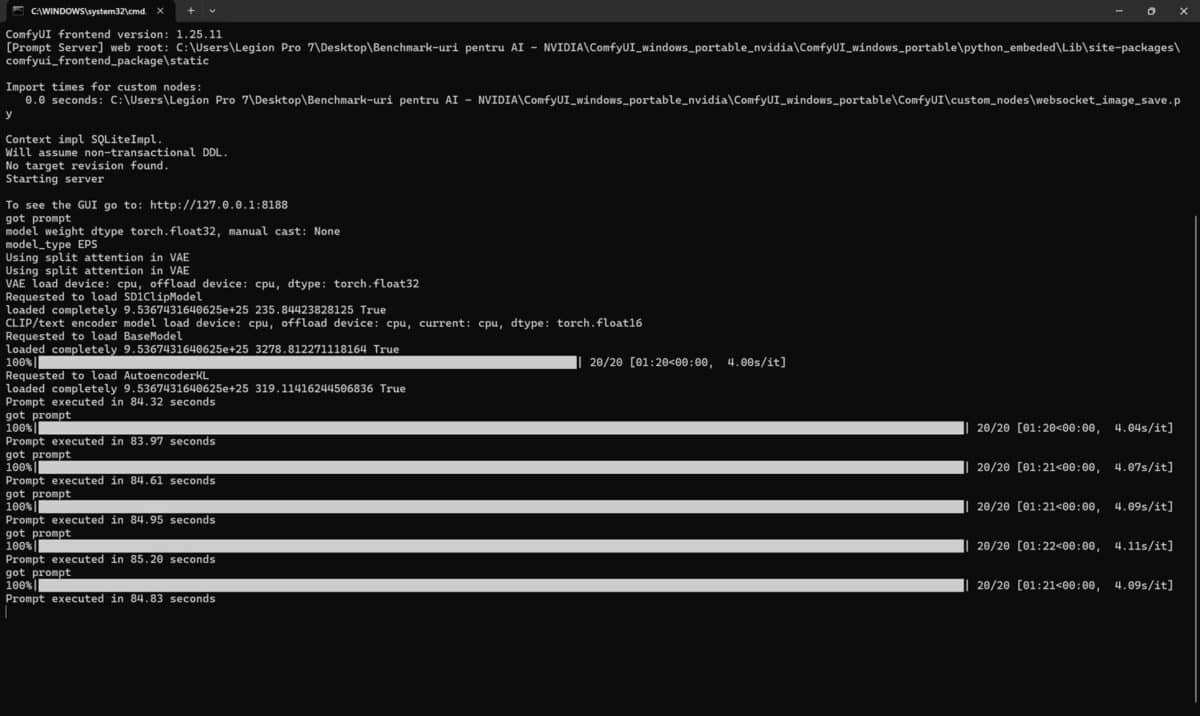
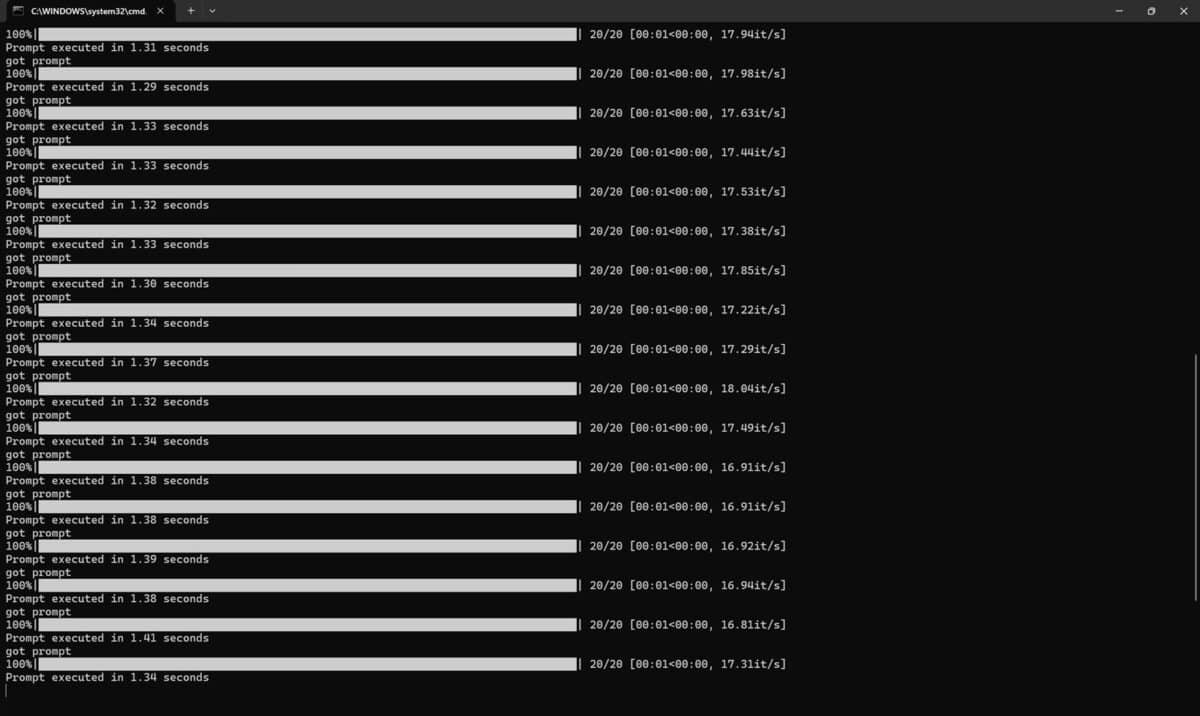
În cazul ComfyUI 0.3.5 avem capturi de ecran foarte elocvente din care vedem timpul de randare a aceluiași template. Doar cu CPU durata medie de generare a rezultatului este de circa 84 de secunde, în timp ce cu NVIDIA GeForce RTX 5080 așteptarea s-a redus la numai 1.3 – 1.4 secunde ! Sincer, cât dura o singură randare doar cu CPU puteam randa cu RTX 5080 în jur de 60 de rezultate. Cum vi se pare?
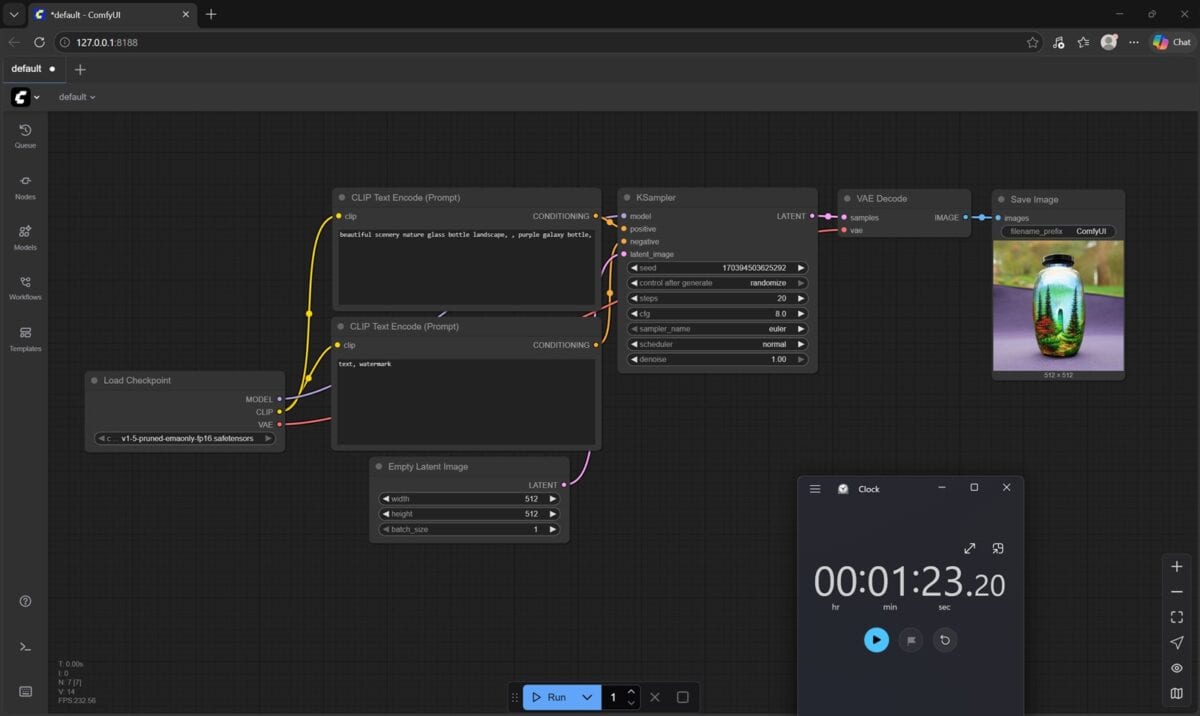
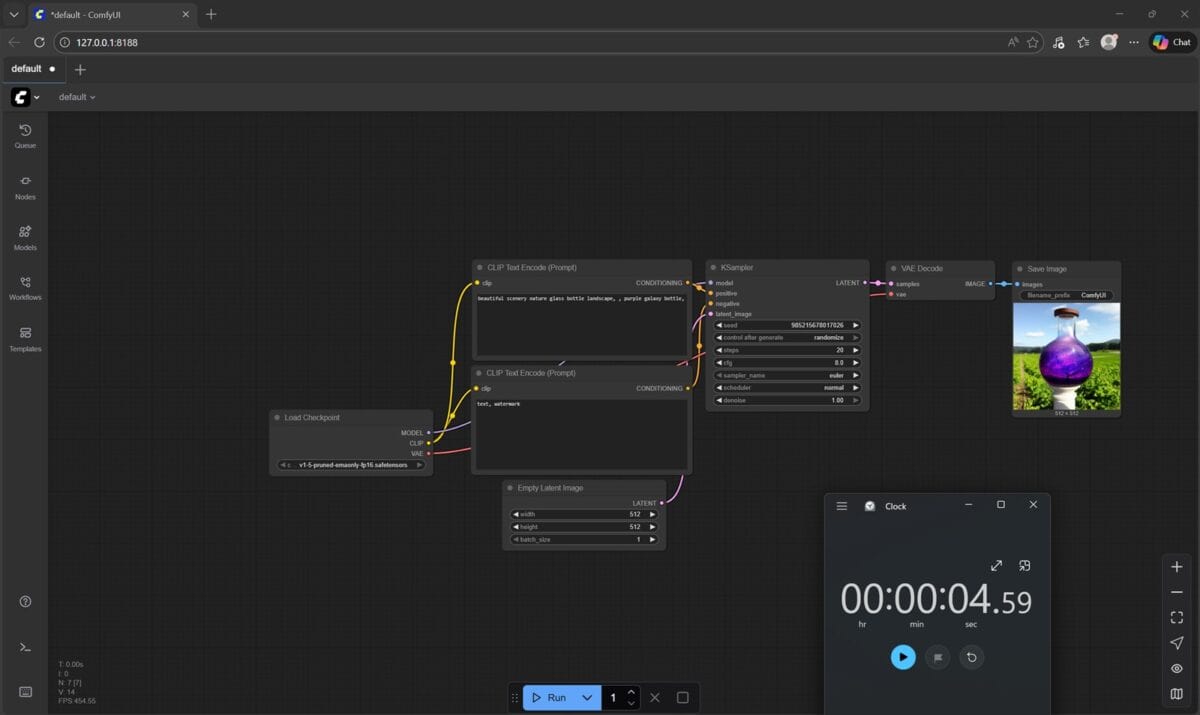
În ComfyUI 0.8.25 nu am mai avut parte de detalii, de log-uri cu duratele, așa că am fost nevoit să folosesc cronometrul din Windows. Doar că nu puteam fi suficient de rapid spre a opri la timp cronometrul când NVIDIA GeForce RTX 5080 Laptop randa rezultatul, așa că în captura de mai sus apar undeva la 4 secunde, fiind în fapt vorba tot despre circa 1.5 secunde. Când a randat doar procesorul Intel, durata a fost de peste 1 minut și 20 de secunde, deci undeva tot la mai mult de 80 de secunde.
Nici nu știu dacă avea rost să rulez atât de multe teste spre a demonstra, încă o dată, că un PC cu placă video dedicată NVIDIA RTX 50 face o diferență uriașă când ai nevoie să folosești programe ce rulează AI local. Sigur că soluțiile AI accesibile online, pe internet, pot reprezenta alternative viabile la cele locale, însă ce te faci cu tot ce ține de confidențialitate, de intimitate?! Când rulezi AI local, tot ce-i pui la dispoziția programului / aplicației rămâne stocat și folosit strict local, deci nimeni și nimic nu-ți va mai accesa acele date, acele informații. Și sunt documente, imagini și alte informații personale pe care chiar nu vrei să le pui pe tava AI-ului online, nu-i așa?
Acest articol este susținut de NVIDIA.
{kind=link}