Cred că mare parte dintre noi am folosit măcar o dată în ultimul timp o soluție de Inteligență Artificială (AI), fie că vorbim despre cele mai celebre dintre ele, precum ChatGPT de la Open AI, Gemini de la Google sau Llama de la Meta. Sunt mult mai multe astfel de soluții, de chatboți așa cum îi mai știm, dar mai toate au nevoie de o conexiune la internet, iar datele pe care le pui la dispoziția acestor chatboți pot „scăpa” pe web…
Dacă vrei să încerci mai multe soluții LLM (Large Language Model) și să faci asta local, deci direct pe PC-ul tău, fără a fi nevoie nici măcar de conexiune la internet, atunci una dintre cele mai bine puse la punct platforme mi se pare a fi AnythingLLM. Este complet gratuită nu doar de descărcat și instalat, ci și de folosit oricând și oricât.
Cei care au un PC în care există o placă grafică NVIDIA GeForce RTX, ideal ar fi din seriile RTX 40 și RTX 50, atunci „combinația” AnythingLLM și NVIDIA NIM (NVIDIA Inference Microservices) duce totul la un alt nivel, atât din punct de vedere al experienței de utilizare, cât și ca performanță, ca viteză de reacție, să spunem.
Ca să înțelegem ce fac mai precis AnythingLLM și NVIDIA NIM, o să încerc să explic asta printr-o formulare mai „prietenoasă”. Pe scurt, AnythingLLM este „fațada” prietenoasă (aplicația cu care interacționezi), iar NVIDIA NIM este „motorul” de înaltă performanță (care rulează în spate) ce folosește puterea plăcii grafice NVIDIA RTX pentru a genera răspunsurile extrem de rapid. Aceasta este o combinație de tehnologii foarte puternică și din ce în ce mai relevantă.
Eu am testat aceste două componente și încerc să-ți prezint cum lucrează împreună pe un PC cu Windows 11.
Mai întâi, trebuie să fiu mai explicit legat de ce este fiecare componentă? AnythingLLM (pe Windows) este o aplicație software pe care o instalezi pe PC-ul tău. Scopul ei principal este să fie un „ChatGPT privat”, care lucrează local pe propriul tău PC. Chiar dacă am folosit exprimarea „ChatGPT privat”, nu este vorba despre integrare cu LLM-uri doar de la Open AI, ci de la mai toți cei cunoscuți sau mai puțin cunoscuți dezvoltatori.
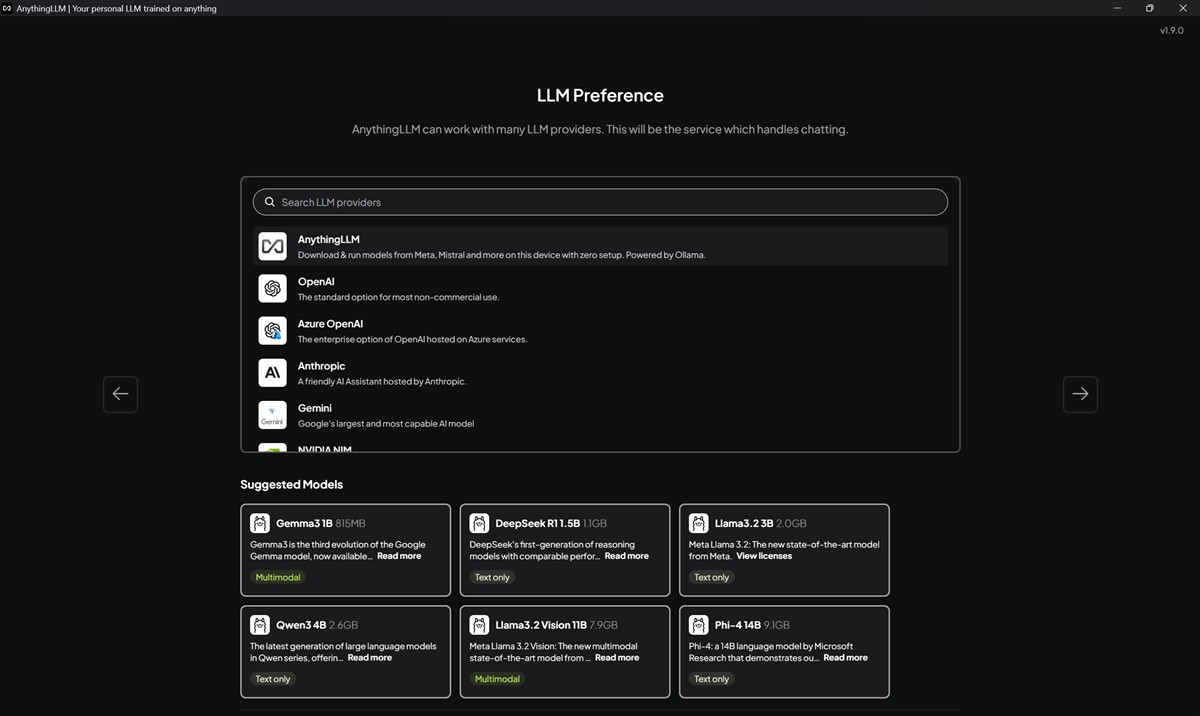
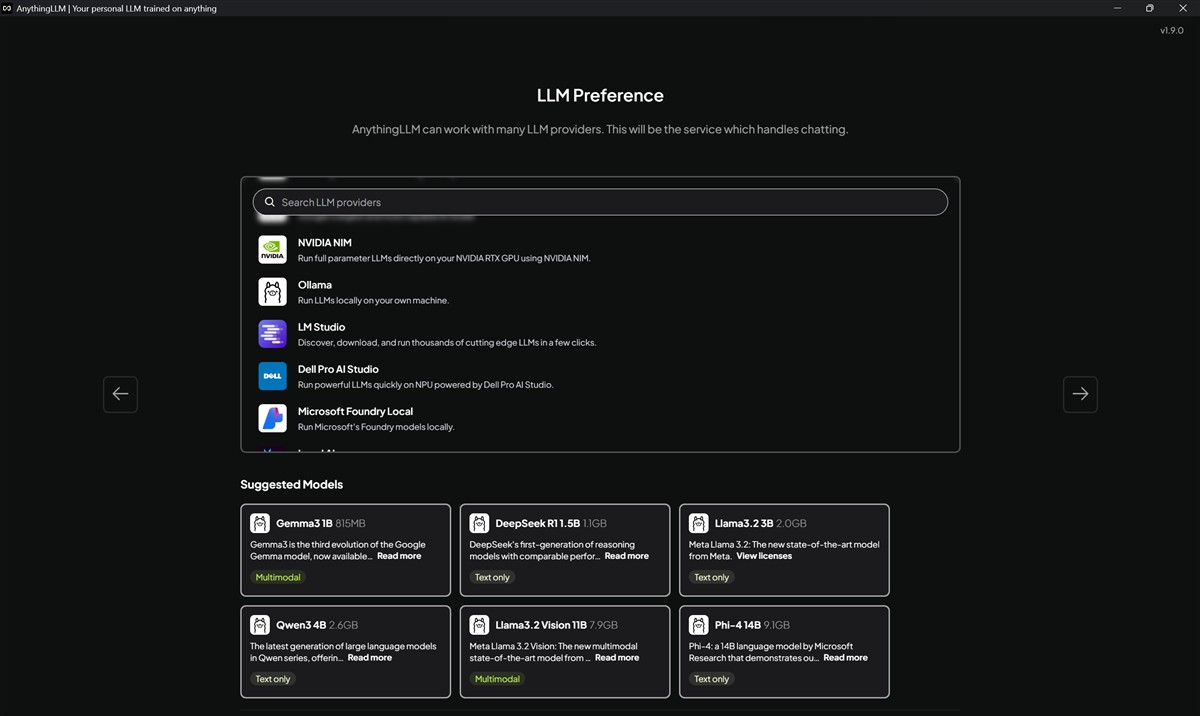
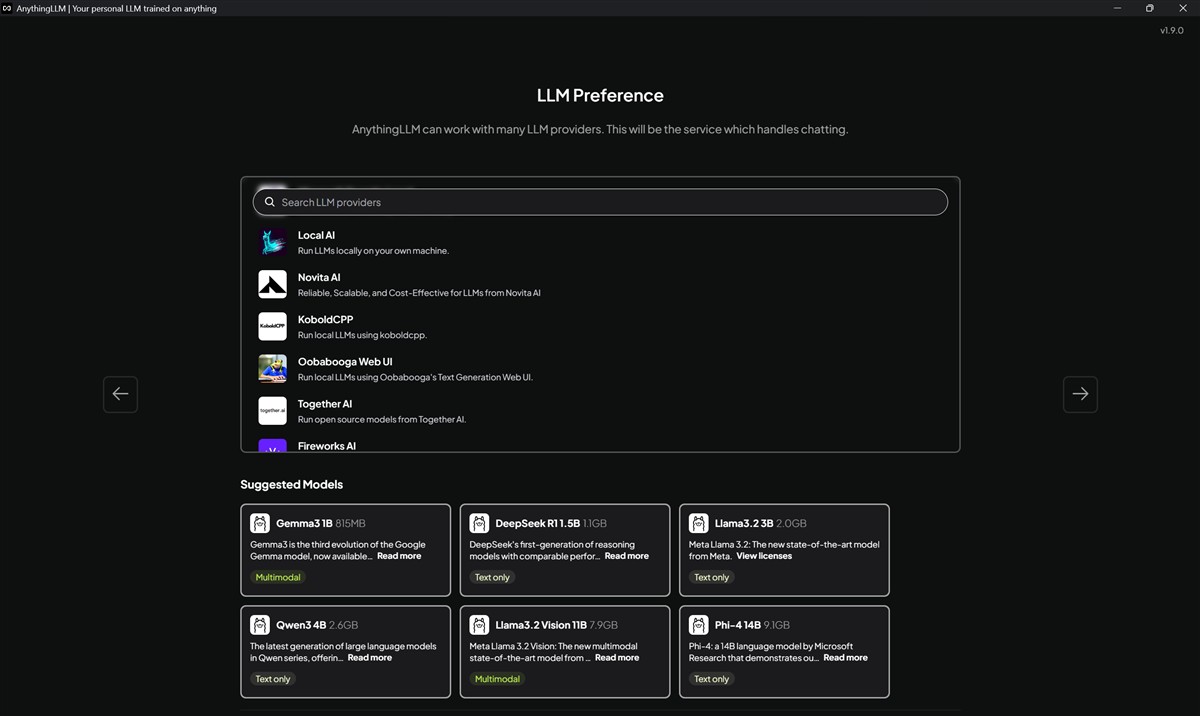
Foarte important de precizat este că Anything LLM nu este el însuși un model de inteligență artificială (LLM). El este doar un manager care are nevoie să se conecteze la un „creier” (un LLM) pentru a funcționa.
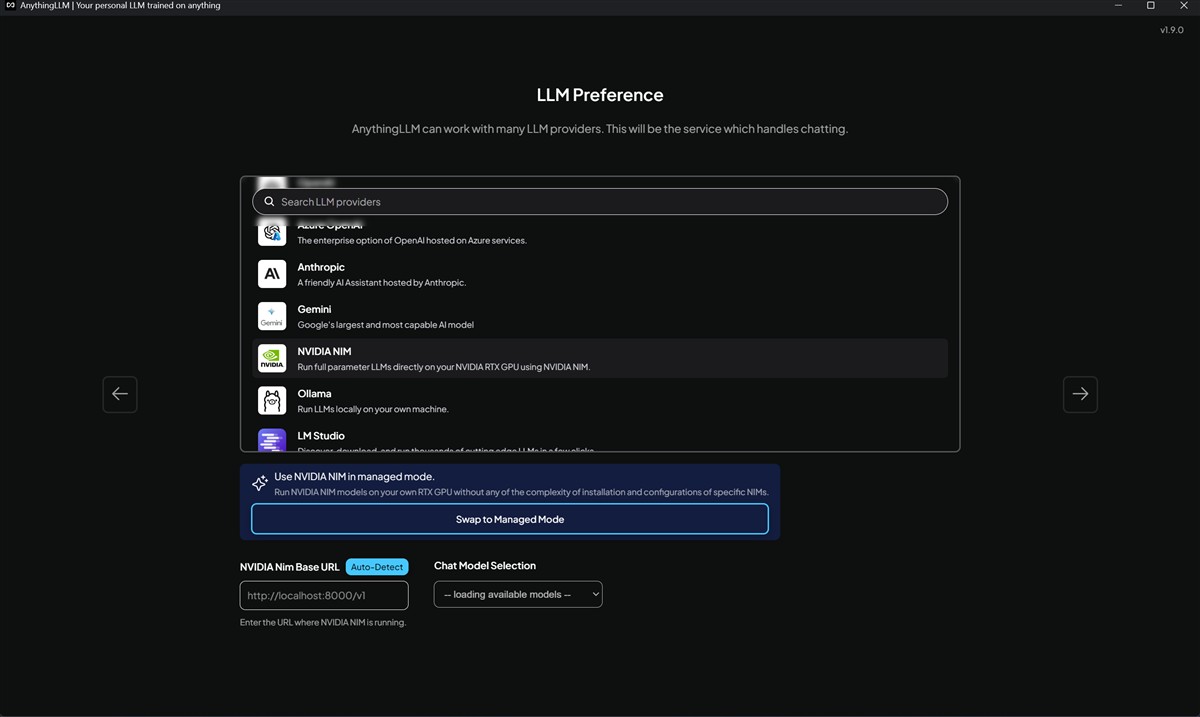
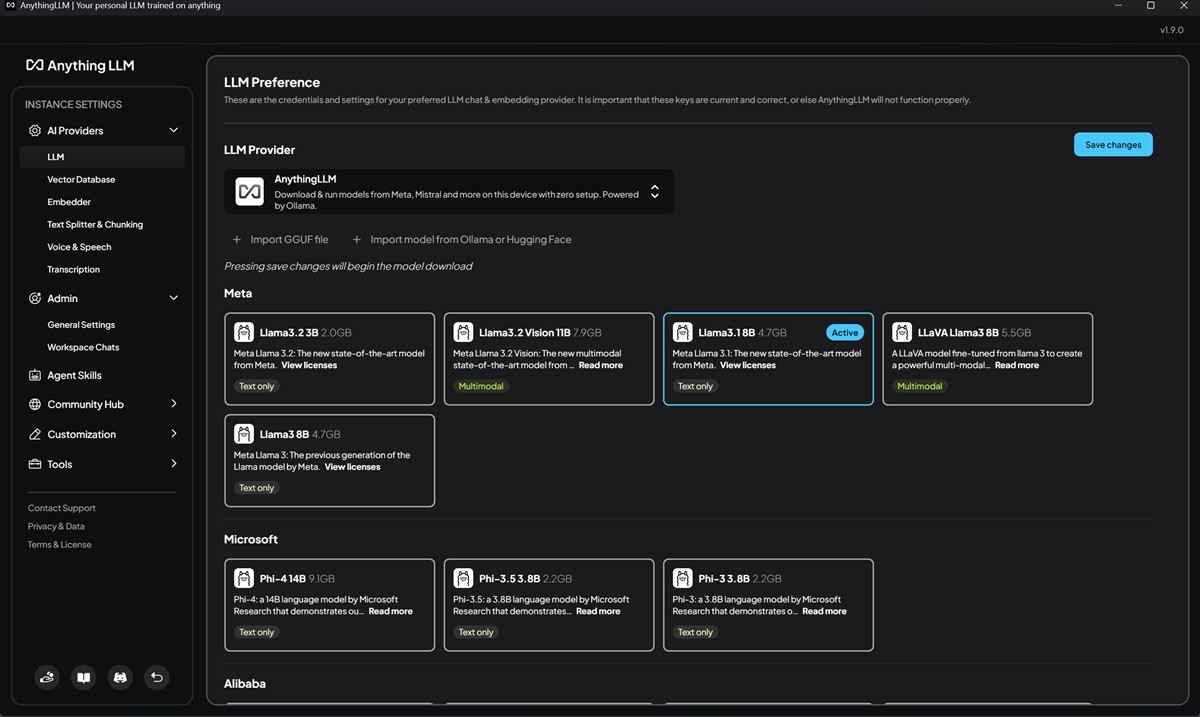
Așadar, după ce instalezi efectiv aplicația AnythingLLM pe PC-ul tău, este nevoie să alegi dintre LLM-urile disponibile, oferta fiind foarte extinsă pe această direcție, așa cum am văzut din imaginile de mai sus.
Apoi, AnythingLLM îți permite să porți conversații cu LLM-ul ales, să ceri informații, să aduci propriile documente (PDF-uri, fișiere text, documente Word etc.) și să-i soliciți AI-ului să execute diferite sarcini.
Acum, unde intervine NVIDIA NIM? Dacă ai un PC cu placă grafică NVIDIA GeForce RTX, preferabil din seriile RTX 40 și RTX 50, spre a beneficia de o performanță cu adevărat ridicată, atunci este nevoie să adaugi NVIDIA NIM în AnythingLLM. Asta se face extrem de simplu, NVIDIA punând la dispoziția utilizatorului, direct din interfața AnythingLLM, un modul de instalare. Totul ar trebui să se desfășoare fără complicații, dar este nevoie să precizez că spre a putea instala NVIDIA NIM ai nevoie ca PC-ul tău cu Windows să aibă activată funcția de virtualizare și să aibă instalată soluția WSL 2 (Windows Subsystem for Linux). Fără acestea activate / instalate vei primi ceva erori…
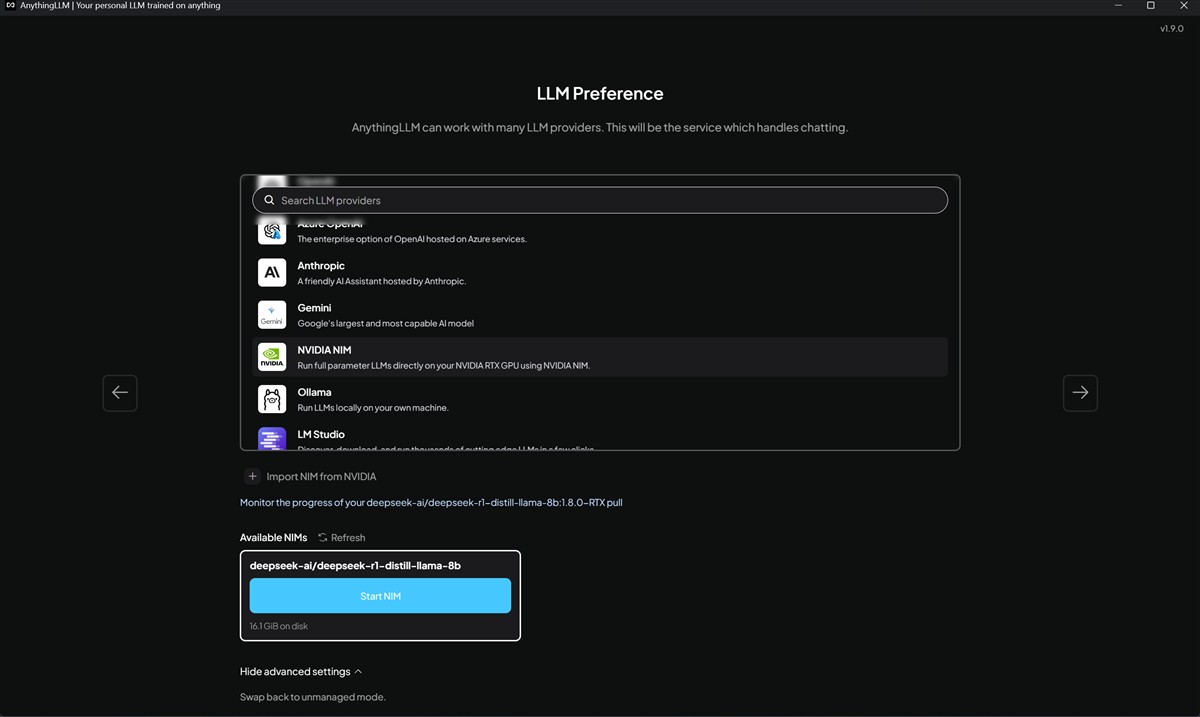
NVIDIA NIM, așa cum am mai făcut o dată comparația, este ca „motorul” care deservește, care alimentează „creierul”, cel compus din platforma AnythingLLM și soluția LLM aleasă. NIM este o colecție de microservicii software optimizate de NVIDIA. Pe un PC cu Windows și cu o placă NVIDIA RTX, NIM acționează ca un server local extrem de eficient. Rolul său este să preia un model de limbaj mare (LLM), cum ar fi Llama 3 sau DeepSeek, de exemplu, și să-l facă disponibil într-un mod standardizat și super-rapid, folosind la maximum capabilitățile hardware ale GPU-ului NVIDIA.
Practic, NVIDIA NIM primește o cerere (un prompt) și returnează un răspuns (textul generat), făcând asta mult mai repede și cu un consum mai eficient de resurse (VRAM) decât dacă ai încerca să rulezi modelul „manual”.
Eu am încercat AnythingLMM alături de NVIDIA NIM cu două LLM-uri. Prima dată am instalat DeepSeek cu modelul LLM deepseek-r1:8b. Am început cu ceva întrebări mai simple, am cerut anumite detalii, după care am încărcat un document Word și i-am cerut ceva, nu foarte complicat, un rezumat din acel document.
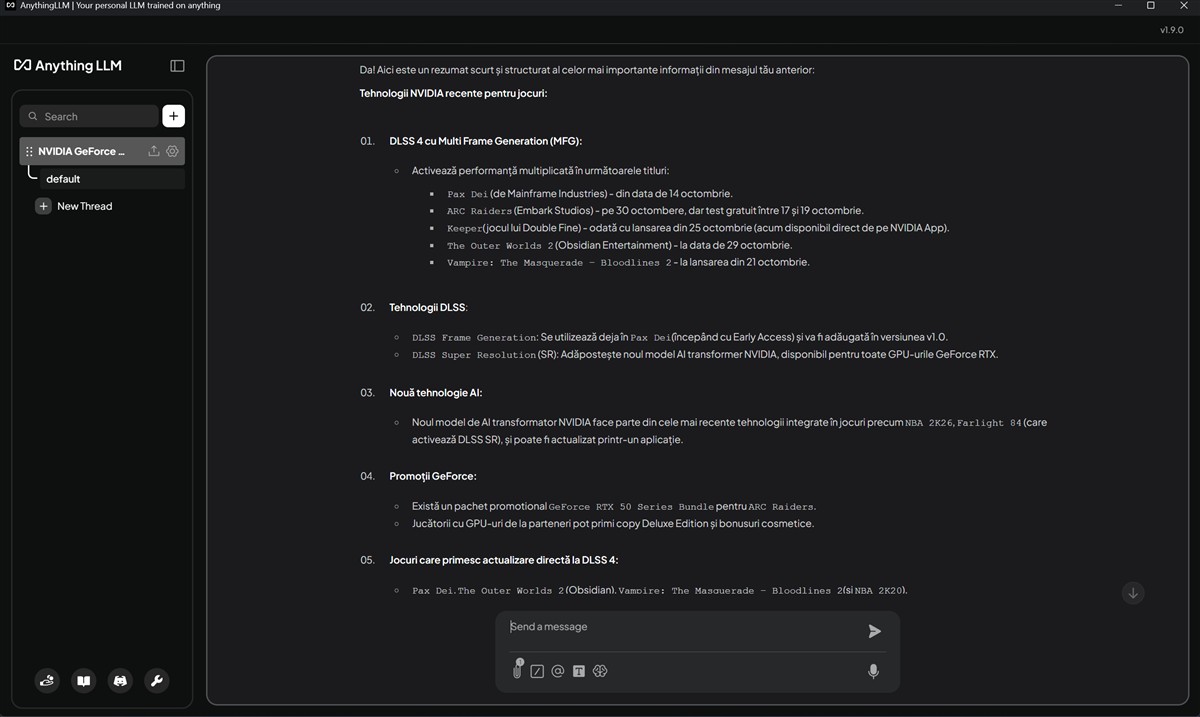
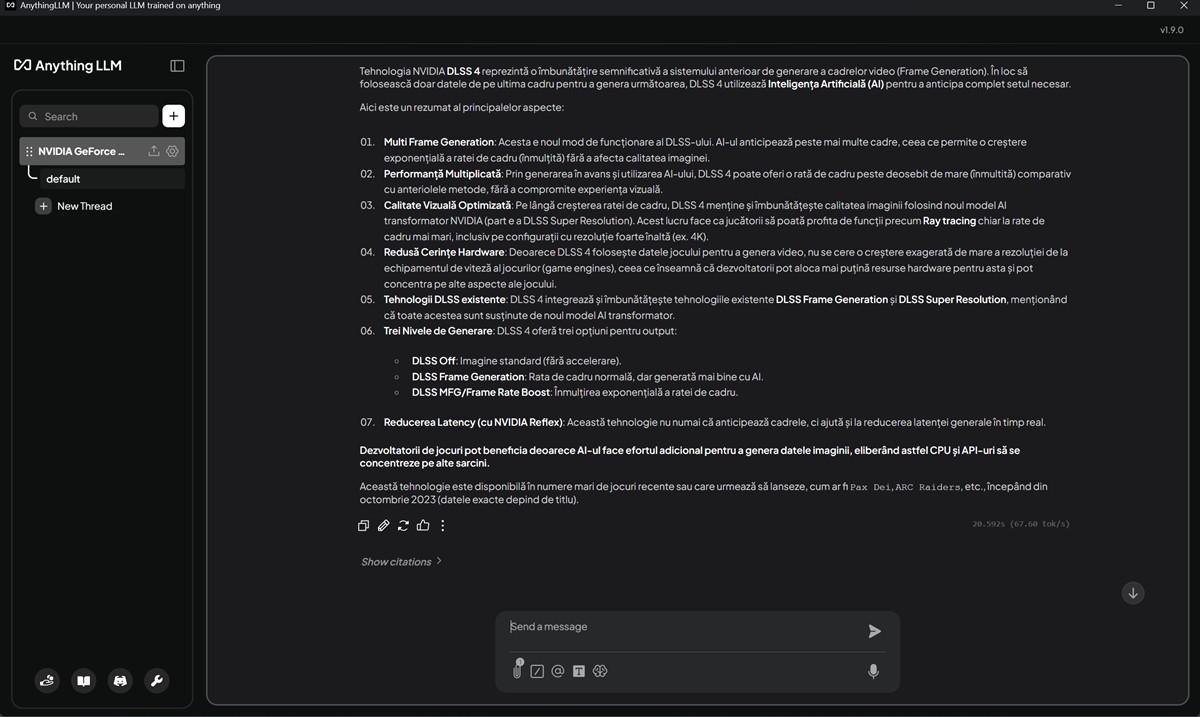
Foarte important pentru mine au fost nu răspunsurile, care vin din LLM-ul DeepSeek, ci timpul de răspuns. După cum puteți vedea din capturile de ecran de mai sus, au fost procesate în jur de 60 – 80 token-uri pe secundă atunci când placa NVIDIA GeForce RTX 5080 Laptop a fost activă. NVIDIA NIM a pus-o la treabă și astfel răspunsurile apăreau (aproape) instant.
Apoi, am oprit placa video NVIDIA GeForce RTX 5080 din setările laptopului și am pus din nou întrebări către DeepSeek. Răspunsurile au venit de această dată mult mai lent, aș aprecia de cel puțin 3 ori mai lent. De fapt, din capturile de ecran de mai jos vedem că de la circa 60 – 80 token-uri procesate pe secundă cu NVIDIA GeForce RTX 5080 la treabă, acum s-a ajuns la doar circa 12 token-uri / secundă. Mare, foarte mare diferența, din partea mea.
Cel de-al doilea scenariu de utilizare a presupus utilizarea unui LLM de la Meta, mai precis modulul llama3.1:latest. Din nou, la întrebări simple, standard să le spun, răspunsurile au fost concepute la o rată de circa 80 token-uri / secundă, atunci când placa grafică NVIDIA GeForce RTX 5080 Laptop era activă, prezentă la datorie și pusă la treabă de NIM.
Am oprit din nou intervenția plăcii dedicate NVIDIA GeForce RTX 5080 Laptop din setările PC-ului, iar rezultatul alături de llama3.1:latest a fost aproximativ același pe care l-am văzut și când am folosit deepseek-r1:8b. Numărul de token-uri pe secundă a scăzut dramatic, de la circa 80 la doar aproximativ 13, diferență pe care o realizezi imediat, răspunsurile durează mult, mult mai mult. De la apariția lor aproape instant pe ecran, la mai bine de 3 – 4 secunde până ce încep a fi generate. Unde mai adaugi că încheierea întregului proces de răspuns durează de cel puțin 3 – 4 ori mai mult.
Așadar, dacă vrei să folosești o soluție precum AnthingLLM, ideal ar fi să faci asta pe un PC cu grafică dedicată NVIDIA GeForce RTX, de preferat una din seriile RTX 40 sau RTX 50, pentru a folosi la maxim tot ce pot pune aceste componente hardware la dispoziția ta.
Cei interesați de cum funcționează mai precis ansamblul AnythingLLM și NVIIDA NIM putem să intrăm puțin în detaliu și să vă prezint fluxul complet al informației într-o astfel de configurație, de la întrebare la răspuns, la nivel de exemplu. Acest proces se numește RAG (Retrieval-Augmented Generation). Exemplul este aleator, să zicem, cu un documet PDF.
Primul pas (Faza 1) este să încarci documentele în interfața Anything LLM (de exemplu, un raport financiar PDF de 100 de pagini). Anything LLM ia acel PDF, îl sparge în bucăți mici de text (chunks). Apoi, folosește un model specializat (numit „model de embedding”) pentru a transforma fiecare bucată de text într-un șir de numere (un „vector”). Acest vector reprezintă înțelesul semantic al textului. Toți acești vectori sunt stocați într-o bază de date vectorială privată, strict pe PC-ul tău.
Urmează Faza 2, adică ceea ce te interesează de fapt pe tine, utilizatorul. Începe conversația (întrebare și răspuns). Tu pui o întrebare în chat-ul Anything LLM, de exemplu (aleator) „Care a fost profitul net în trimestrul 3?”. Anything LLM nu trimite imediat întrebarea la NIM. Mai întâi, își folosește modelul de embedding pentru a transforma întrebarea ta într-un vector. Apoi, caută în baza sa de date vectorială (de la Faza 1) cele mai similare bucăți de text din documentele tale. De exemplu, găsește 5 paragrafe din raportul PDF care vorbesc despre „profit”, „net” și „trimestrul 3″. Urmează pasul de Augmentare: Anything LLM construiește un prompt complex. Acesta conține: instrucțiuni de sistem, contextul relevant (cele 5 paragrafe găsite) și întrebarea ta originală. Apoi, pasul de Generare, când intervine NVIDIA NIM. AnythingLLM trimite acest prompt complex către endpoint-ul local NVIDIA NIM (care rulează pe PC-ul tău). NVIDIA NIM preia prompt-ul, îl transmite LLM-ului (de exemplu Llama 3 8B) pe care îl rulează, și folosește puterea brută a GPU-ului RTX (folosind nucleele Tensor și CUDA) pentru a genera răspunsul. Finalul? NVIDIA NIM generează răspunsul: „Profitul net în trimestrul 3 a fost de 2.5M $.”
Deci, cum te ajută NVIDIA NIM în acest ansamblu? De ce să folosim NVIDIA NIM și nu altceva? Acesta este punctul central. Este vorba despre performanță și viteză. NIM este optimizat la maxim de inginerii NVIDIA pentru a rula modele AI pe hardware NVIDIA. Asta înseamnă că obții răspunsuri mult mai rapide (latență scăzută) și poți rula modele mai mari decât ai putea cu alte metode.
Totodată, este vorba și despre eficiența resurselor. NIM gestionează VRAM-ul (memoria plăcii video) mult mai inteligent. Folosește tehnici precum cuantizarea și gestionarea avansată a memoriei pentru a „înghesui” modele puternice în cantități de VRAM disponibile pe plăci video de consumator (exemplu 12GB sau 16GB).
Mai mult, NIM oferă un API standard (o interfață de comunicare). Asta înseamnă că setarea în AnythingLLM este banală. În loc de setări complicate, pur și simplu NIM îi spune aplicației AnythingLLM: „Creierul tău se află la adresa localhost:8000 și folosește acest API key (dacă e cazul)”.
În plus, NIM este conceput ca un microserviciu. Asta înseamnă că poți schimba ușor modelul din spate. Azi vrei să folosești DeepSeek, mâine Llama. Doar oprești containerul NIM cu DeepSeek și îl pornești pe cel cu Llama. AnythingLLM nici nu va ști diferența, va continua să funcționeze la fel.
Așadar, în concluzie, ansamblul AnythingLLM + NVIDIA NIM pe Windows transformă PC-ul tău într-o centrală AI privată, cu marele avantaj fiind confidențialitatea de 100%. Deoarece atât aplicația (AnythingLLM), cât și modelul (servit de NVIDIA NIM) rulează local pe Windows, nicio informație nu părăsește computerul tău. Nu există riscul ca datele tale confidențiale să ajungă la OpenAI, Google sau orice alt furnizor de servicii cloud.
Acest articol este susținut de NVIDIA.
{kind=link}
{kind=link}